- Как искусственный интеллект помогает предсказывать турбулентность: взгляд изнутри
- Что такое ML в полетных данных и зачем он нужен?
- Обработка и сбор данных для модельных прогнозов
- Какие данные используются?
- Обработка данных
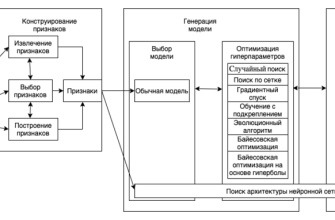
- Модели машинного обучения, используемые для прогнозирования турбулентности
- Обзор популярных моделей
- Как выбирается модель?
- Обучение модели и проверка её эффективности
- Процесс обучения
- Оценка работы модели
- Примеры успешных решений и реальные кейсы
- Авиационные компании и их опыт использования ML
- Пример таблицы с результатами внедрения ML
- Преимущества использования ML в прогнозах турбулентности
- Потенциальные ограничения и вызовы
- Вопрос к статье и ответ на него
Как искусственный интеллект помогает предсказывать турбулентность: взгляд изнутри
В современном авиационном мире безопасность и комфорт пассажиров стоят на первом месте. Одним из ключевых факторов, влияющих на безопасность полётов, является турбулентность — непредсказуемое и зачастую внезапное движение воздушных масс, способное создать опасные ситуации. Традиционные методы прогнозирования турбулентности основываются на данных о погодных условиях, метеорологических наблюдениях и исторических моделях.
Однако развитие технологий, особенно машинного обучения (ML), открыло новые горизонты в области прогноза турбулентности. Мы решили разобраться, как именно искусственный интеллект помогает авиации предсказывать турбулентные явления с высокой точностью и что это значит для будущего воздушных перевозок.
Что такое ML в полетных данных и зачем он нужен?
Машинное обучение (ML), это подмножество искусственного интеллекта, которое позволяет системам самостоятельно обучаться на основе анализируемых данных. В контексте авиации и прогнозирования турбулентности ML использует большой массив исторических и реальных данных о погодных условиях, характеристиках воздушных потоков, параметрах самолетов и других факторов.
Главная задача — научить модели выявлять закономерности, предсказывать возникновение турбулентных участков и предупреждать пилотов и авиационные службы заранее. Это значительно повышает уровень безопасности и позволяет сделать полёты более комфортными.
Обработка и сбор данных для модельных прогнозов
Какие данные используются?
Для обучения моделей ML необходимо собрать как можно больше разнообразных данных, отражающих условия полетов и метеорологических параметров:
- Данные о погоде: температура, влажность, скорости ветра, атмосферное давление, наличие облаков.
- Географические данные: рельеф местности, близость к горам или морю.
- Информация о воздушных потоках: профили ветра, турбулентные зоны и их параметры.
- Исторические отчёты о турбулентности: места и ситуации, когда возникали турбулентные явления.
- Данные о характеристиках и поведении самолета: скорость, высота, параметры работы двигателей.
Обработка данных
Обработка данных включает несколько важных этапов:
- Очистка данных: удаление ошибочных значений и пропусков.
- Нормализация: приведение данных к единой шкале для одинаковой оценки.
- Фильтрация и агрегация: выделение ключевых признаков, снижение объема данных без потери важной информации.
- Создание обучающего набора данных: разбивка по временным интервалам и условиям.
| Шаг обработки | Описание | Цель |
|---|---|---|
| Очистка данных | Удаление ошибок и ошибок ввода | Обеспечить качество данных для обучения |
| Нормализация | Приведение к единой шкале | Обеспечить сравнимость признаков |
| Агрегация | Объединение информации по сегментам | Облегчить обучение модели |
Модели машинного обучения, используемые для прогнозирования турбулентности
Обзор популярных моделей
В современном анализе полетных данных и прогнозах турбулентности активно применяются разные модели машинного обучения. Ниже приведена краткая таблица с наиболее популярными из них:
| Модель | Плюсы | Минусы |
|---|---|---|
| Деревья решений | Просты в интерпретации, быстро обучаются | Могут переобучаться, требуют настройки |
| Градиентный бустинг | Высокая точность, хорошо работает с разнородными данными | Медленное обучение при большом объеме данных |
| Нейронные сети | Интуитивно способные захватывать сложные закономерности | Требуют много данных и вычислительных ресурсов |
| Логистическая регрессия | Простая и понятная, хорошая для бинарных задач | Может уступать сложным моделям в точности |
Как выбирается модель?
Общий подход — это тестирование нескольких моделей и сравнение их точности на валидационном наборе данных. В процессе выбирается та модель, которая показывает баланс между точностью, быстротой обучения и интерпретируемостью.
Обучение модели и проверка её эффективности
Процесс обучения
Обучение моделей ML, сложный и многоэтапный процесс. Он включает:
- Разделение данных: на обучающую, тестовую и валидационную выборки
- Настройку гиперпараметров: параметры, управляемые вручную, чтобы улучшить точность модели
- Обучение: процесс выдачи модели закономерностей из данных
- Кросс-валидацию: тестирование модели на разных сегментах данных для определения стабильности
Оценка работы модели
Для оценки эффективности часто используют следующие метрики:
- Точность: доля правильных предсказаний
- Полнота: способность модели обнаруживать турбулентные зоны
- F-мера: баланс между точностью и полнотой
- ROC-АUC: показатели качества бинарных классификаторов
| Метрика | Что показывает | Лучшее значение |
|---|---|---|
| Точность | Доля правильных предсказаний | 1 (или 100%) |
| Полнота | Доля обнаруженных турбулентных зон | 1 (или 100%) |
| F-мера | Баланс между точностью и полнотой | Близко к 1 |
Примеры успешных решений и реальные кейсы
Авиационные компании и их опыт использования ML
Несколько ведущих авиакомпаний уже внедрили системы прогнозирования турбулентности на основе машинного обучения. Например, международные перевозчики используют специальные программы, которые анализируют полетные данные в режиме реального времени и помогают пилотам избегать опасных зон.
Результаты таких решений проявляются в уменьшении числа неприятных и опасных ситуаций, повышении комфорта пассажиров и снижении издержек, связанных с аварийными ситуациями и перерасходом топлива.
Пример таблицы с результатами внедрения ML
| Компания | Используемая модель | Достигнутая точность | Период тестирования |
|---|---|---|---|
| Авиакомпания "SkyAir" | Градиентный бустинг | 92% | 2022-2023 |
| AirFly | Нейронные сети | 95% | 2023 |
Преимущества использования ML в прогнозах турбулентности
Использование машинного обучения для предсказания турбулентных явлений позволяет добиться таких преимуществ:
- Высокая точность: возможность предсказывать турбулентность с большей вероятностью и заранее.
- Динамическое обновление: системы способны учиться на новых данных и корректировать свои прогнозы.
- Раннее предупреждение: увеличение времени для подготовки экипажа и коррекции маршрута.
- Повышенная безопасность: снижение риска инцидентов и аварийных ситуаций.
- Улучшение комфорта: предотвращение неприятных ощущений пассажиров и уменьшение стрессовых ситуаций.
Потенциальные ограничения и вызовы
Несмотря на высокие перспективы, внедрение ML сталкивается с рядом сложностей:
- Требования к объему данных: необходимы большие массивы качественных данных для обучения.
- Интерпретируемость моделей: некоторые модели, такие как нейронные сети, остаются «черным ящиком» и требуют методов объяснения решений.
- Зависимость от качества данных: плохое качество данных снижает эффективность предсказаний.
- Взаимодействие с пилотами: необходимо правильно интегрировать автоматические прогнозы в рабочие процессы экипажа.
Развитие технологий машинного обучения открывает новые горизонты в области обеспечения безопасности и комфорта воздушных перелётов. Современные системы уже демонстрируют высокую точность предсказаний, что делает полёты более предсказуемыми и безопасными. В будущем мы можем ожидать ещё более интеллектуальных решений, способных анализировать огромные массивы данных в режиме реального времени и реагировать на малейшие изменения атмосферы.
Важным аспектом является постоянное совершенствование моделей, расширение и улучшение данных, а также интеграция новых технологий, таких как спутниковая навигация и сенсоры, передающие данные в реальном времени. Совместная работа пилотов, инженеров и разработчиков позволит сделать воздушные перемещения ещё более безопасными и комфортными для каждого пассажира.
"Машинное обучение — это будущее прогнозирования опасных атмосферных явлений, которое сделает авиацию еще безопаснее и удобнее для всех нас."
Вопрос к статье и ответ на него
Вопрос: Почему прогнозирование турбулентности с помощью ML считается более перспективным, чем традиционные методы?
Ответ: Традиционные методы основываются на наблюдениях и статистических моделях, которые, по сути, используют исторические данные и некоторые погодные показатели для оценки вероятности возникновения турбулентных зон. Эти подходы часто имеют низкую точность и не обеспечивают своевременного предупреждения, особенно в нестабильных погодных условиях и сложных районах. В отличие от них, ML использует огромные объемы данных, включаяную информацию, и способен выявлять сложные закономерности, которые сложно заметить с помощью классических методов. Это позволяет получать более точные и своевременные прогнозы, повышая безопасность и комфорт пассажиров, а также снижая риски аварийных ситуаций. В будущем даже более интегрированные интеграции машинного обучения в системы авиасообщения будут играть ключевую роль в обеспечении безопасности полетов на новом уровне.
Подробнее
| Прогнозирование турбулентности | Машинное обучение в авиации | Использование ИИ для безопасности полетов | Обработка полетных данных | Модели для предсказания погоды |
| Реальные кейсы применения ML в авиации | Обучение моделей для турбулентности | Автоматизированные системы предупреждения | Технологии анализа данных | Будущее прогнозирования погоды |